Chạy LLM Cục Bộ Trên VPS: Hướng Dẫn Chi Tiết Sử Dụng Ollama Và LM Studio
Slug: chay-llm-cuc-bo-tren-vps-ollama-lm-studio
Mô tả: Hướng dẫn từng bước cài đặt và sử dụng Ollama và LM Studio để chạy các mô hình ngôn ngữ lớn cục bộ trên VPS. Tiết kiệm chi phí, bảo mật dữ liệu và kiểm soát hoàn toàn.
Danh mục: Công Nghệ AI
Trong thời đại AI bùng nổ, việc sử dụng các mô hình ngôn ngữ lớn (LLM) đã trở thành nhu cầu thiết yếu cho nhiều doanh nghiệp và nhà phát triển. Tuy nhiên, chi phí API của các dịch vụ cloud như OpenAI có thể lên tới hàng trăm đô la mỗi tháng. Giải pháp chạy LLM cục bộ trên VPS với Ollama và LM Studio không chỉ giúp tiết kiệm chi phí mà còn đảm bảo quyền riêng tư dữ liệu tuyệt đối.
Lợi Ích Của Việc Chạy LLM Cục Bộ

Chạy LLM cục bộ mang lại nhiều ưu điểm vượt trội so với việc sử dụng API cloud. Đầu tiên là tiết kiệm chi phí đáng kể – sau khi đầu tư ban đầu cho VPS, bạn có thể thực hiện không giới hạn request mà không lo ngại về hóa đơn hàng tháng.
Bảo mật dữ liệu là yếu tố quan trọng khác. Dữ liệu của bạn hoàn toàn không rời khỏi server, đặc biệt phù hợp cho các ngành như tài chính, y tế, pháp lý – nơi yêu cầu bảo mật thông tin nghiêm ngặt. Bạn cũng có quyền kiểm soát hoàn toàn mô hình, từ việc fine-tuning cho nhu cầu cụ thể đến tùy chỉnh các tham số inference.
Cuối cùng, khả năng hoạt động offline giúp đảm bảo tính liên tục của ứng dụng ngay cả khi mất kết nối internet, rất hữu ích cho các môi trường làm việc từ xa hoặc vùng có kết nối không ổn định.
Tổng Quan Ollama Và LM Studio

Ollama là một platform mã nguồn mở được thiết kế để đơn giản hóa việc chạy các mô hình ngôn ngữ lớn trên máy cục bộ. Ollama hỗ trợ nhiều mô hình phổ biến như GPT-3.5, Llama 2/3, Mistral, Gemma và DeepSeek. Điểm mạnh của Ollama nằm ở khả năng quản lý mô hình thông qua command line interface đơn giản và API tương thích với OpenAI.
LM Studio là một ứng dụng desktop với giao diện đồ họa thân thiện, được thiết kế để giúp người dùng dễ dàng tải xuống, quản lý và chạy các mô hình LLM. LM Studio tích hợp sẵn trình duyệt mô hình từ Hugging Face, Chat UI trực quan và local server runtime tương thích OpenAI API.
Sự khác biệt chính: Ollama tập trung vào hiệu suất và khả năng tự động hóa thông qua CLI, trong khi LM Studio ưu tiên trải nghiệm người dùng với giao diện trực quan và các tính năng fine-tuning mở rộng.
Cài Đặt Ollama Trên VPS
Yêu Cầu Hệ Thống
Để chạy Ollama hiệu quả trên VPS, bạn cần:
- RAM: Tối thiểu 16GB (khuyến nghị 32GB cho các mô hình lớn)
- Storage: 12GB+ (mỗi mô hình 7B cần khoảng 4-5GB)
- CPU: 4-8 cores
- OS: Ubuntu 22.04+ hoặc Debian stable
- GPU: Không bắt buộc nhưng khuyến khích NVIDIA GPU với CUDA
Quy Trình Cài Đặt
Trước tiên, cập nhật hệ thống và cài đặt các dependencies:
sudo apt update && sudo apt upgrade -y
sudo apt install -y python3 python3-pip git curl
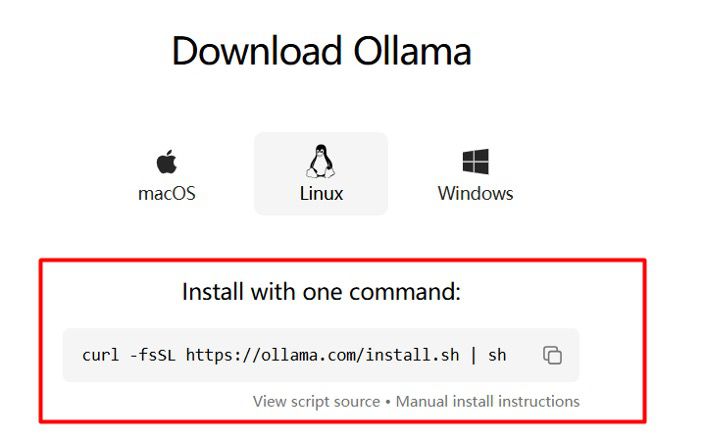
Tải và cài đặt Ollama:
curl -fsSL https://ollama.ai/install.sh | sh
Để cho phép truy cập từ bên ngoài, cần cấu hình environment variables:
sudo systemctl edit ollama
Thêm vào file cấu hình:
<img src="https://www.learnaboutlogistics.com/wp-content/uploads/2016/07/photodune-6221194-customer-service-team-s-e1468394369939-742x353.jpg" alt="Service" />
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=*"
Khởi động lại service:
sudo systemctl daemon-reload
sudo systemctl restart ollama
Tải và Chạy Mô Hình
Tải mô hình Llama 3.1 8B:
ollama pull llama3.1:8b
Chạy mô hình:
ollama run llama3.1:8b
Để chạy ở chế độ background:
nohup env OLLAMA_HOST=0.0.0.0:11434 ollama serve &
Thiết Lập LM Studio
Cài Đặt LM Studio
LM Studio hỗ trợ Windows, macOS và Linux. Tải từ trang chính thức: https://lmstudio.ai
Với Linux, tải file AppImage:
wget https://releases.lmstudio.ai/linux/x64/LM-Studio-0.3.9-6-x64.AppImage
chmod +x LM-Studio-0.3.9-6-x64.AppImage
./LM-Studio-0.3.9-6-x64.AppImage
Tải Và Quản Lý Mô Hình
LM Studio có giao diện tìm kiếm tích hợp kết nối với Hugging Face. Để tải mô hình:
- Mở tab Search trong LM Studio
- Tìm kiếm với từ khóa như “llama gguf” hoặc “mistral gguf”
- Chọn mô hình phù hợp với RAM của bạn
- Nhấn Download và chờ quá trình hoàn tất
Các mô hình GGUF được khuyến nghị:
- TheBloke/Llama-2-7B-Chat-GGUF (4GB)
- TheBloke/Mistral-7B-Instruct-v0.2-GGUF (4.1GB)
- microsoft/DialoGPT-medium-GGUF (1.2GB)
Chạy Local Server
LM Studio có thể hoạt động như một API server tương thích OpenAI:
- Chuyển sang tab Local Server
- Chọn mô hình đã tải
- Cấu hình port (mặc định 1234)
- Nhấn Start Server
Server sẽ chạy tại http://localhost:1234 với các endpoints:
GET /v1/modelsPOST /v1/chat/completionsPOST /v1/completionsPOST /v1/embeddings
So Sánh Và Kết Hợp Hai Công Cụ

Ưu Điểm Ollama
- Hiệu suất cao: Tối ưu hóa cho server, sử dụng ít tài nguyên
- Automation: Dễ dàng tích hợp vào CI/CD pipeline
- Stability: Chạy ổn định ở chế độ production
- API native: Hỗ trợ đầy đủ OpenAI API endpoints
Ưu Điểm LM Studio
- User-friendly: Giao diện trực quan, dễ sử dụng
- Model browser: Tích hợp sẵn trình duyệt Hugging Face
- Fine-tuning: Công cụ fine-tune mạnh mẽ
- Monitoring: Dashboard theo dõi performance chi tiết
Kết Hợp Hiệu Quả
Chiến lược tối ưu là sử dụng LM Studio cho development và Ollama cho production:
- Development stage: Sử dụng LM Studio để thử nghiệm các mô hình, fine-tune parameters và prototype ứng dụng
- Testing stage: Chuyển sang Ollama để test performance và stability
- Production stage: Deploy với Ollama để đảm bảo hiệu suất và độ tin cậy
Bạn cũng có thể chạy song song cả hai: LM Studio cho các tác vụ interactive development, Ollama cho các API endpoints production.
Tối Ưu Hóa Performance Và Bảo Trì

Tối Ưu Hóa Hiệu Suất
Quản lý bộ nhớ: Sử dụng mô hình quantized (Q4KM, Q4KS) để giảm RAM usage mà vẫn duy trì chất lượng output cao. Với mô hình 7B, phiên bản Q4KM chỉ cần khoảng 4GB RAM thay vì 14GB cho phiên bản full precision.
GPU optimization: Nếu VPS có GPU NVIDIA, cài đặt CUDA drivers và cấu hình:
# Cài đặt CUDA
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/3bf863cc.pub
sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/ /"
sudo apt update && sudo apt install cuda-toolkit-12-0
Caching và Load Balancing: Implement Redis để cache responses và sử dụng nginx như reverse proxy:
upstream ollama_backend {
server localhost:11434;
}
server {
listen 80;
location / {
proxy_pass http://ollama_backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
Monitoring Và Maintenance
Thiết lập monitoring để theo dõi resource usage:
# Install htop, nvtop cho GPU monitoring
sudo apt install htop nvtop
# Tạo script monitoring
cat > /usr/local/bin/llm-monitor.sh << 'EOF'
#!/bin/bash
echo "=== LLM Services Status ==="
systemctl status ollama
echo "=== Resource Usage ==="
free -h
df -h /
EOF
chmod +x /usr/local/bin/llm-monitor.sh
Tạo crontab để backup models và logs:
crontab -e
# Thêm dòng sau để backup hàng ngày lúc 2:00 AM
0 2 * * * tar -czf /backup/ollama-models-$(date +%Y%m%d).tar.gz ~/.ollama/models/
Security Considerations
Firewall configuration:
sudo ufw allow 11434/tcp # Ollama
sudo ufw allow 1234/tcp # LM Studio
sudo ufw allow 22/tcp # SSH
sudo ufw enable
Authentication: Implement API key authentication thông qua nginx:
location / {
if ($http_authorization != "Bearer your-secret-api-key") {
return 401;
}
proxy_pass http://localhost:11434;
}
Việc kết hợp Ollama và LM Studio trên VPS tạo ra một giải pháp LLM cục bộ mạnh mẽ, tiết kiệm chi phí và bảo mật cao. Ollama đảm nhận vai trò production server ổn định, trong khi LM Studio hỗ trợ development và experimentation. Với cấu hình phù hợp, bạn có thể có được hiệu suất tương đương các dịch vụ cloud premium mà chi phí chỉ bằng một phần nhỏ, đồng thời đảm bảo quyền riêng tư dữ liệu tuyệt đối.